

こんにちは、Einarです。
ご存じの方も多いと思いますが、私はこれまでに星光の英雄たちのキャラクター向けに、かなりの数のLoRAを作成してきました。
(LoRAについてよく知らない方は、こちらのチュートリアルも参考にしてみてください。)

そもそもLoRA作りを始めたきっかけは、今からおよそ1年前。
自分のキャラクターを安定して生成するのがあまりにも大変だったからです。
例えば――
- まやちゃんのブレスレットが左右の腕を行ったり来たりする
- ゆかちゃんのツインテールが、なぜか毎回おかしな形になる
- 武志さんに至っては……成功率が20回に1回くらい?
- まやちゃんのスーツの話は……まあ、触れないでおきましょう
さすがにこれはどうにかしないと、ということで
「それなら自分で作ってしまおう」と思い立ち、LoRA制作に踏み切りました。
(そのときの話の一部は、昔書いたブログ記事にもまとめています。)

星光の英雄たち

初心者でも簡単!LoRAを使ったAIイラスト生成入門!

どうすれば「ヒロイン」を育てるか?
正直なところ、ここまで長い試行錯誤の旅になるとは思っていませんでした。
失敗を重ね、原因を探し、少しずつ解決策を見つけていく――
そんな経験を積み重ねてきました。
この記事では、その過程で得た知見をもとに、オリジナルキャラクター用LoRAを作るための考え方やポイントを、 ガイド(あるいは実践的なチュートリアル)としてまとめていきます。
本記事は SDXL / Illustrious / NoobAI-XL 系モデルを前提としています。
Qwen や Z-Image などの新しいモデルでは、前提条件が異なる場合がありますのでご注意ください。
問題の核心はどこにある? #

オリジナルキャラクターのLoRAを作るというのは、既存キャラクターのLoRAを作るのとは、まったく別物です。
既存キャラであれば、
・資料が大量に存在していたり
・二次創作を通じてさまざまな表現が蓄積されていたり
と、モデル側が参照できる「共通認識」がすでにあります。
しかし、オリジナルキャラの場合、その唯一の情報源は――
作者本人(この場合は私)だけです。
特にアニメ系キャラクターでは、 見た目の要素そのものが「そのキャラらしさ」を決定づけます。
例えば……まやちゃんが金髪だったら、どう思います?

ごめん、まやちゃん!あくまで例えだから!
ここで言いたいのは、アニメキャラ――そしてオリジナルアニメキャラには、
私が 視覚的アイデンティティ(=見た目の一貫性) と呼んでいるものがある、ということです。
それは、そのキャラをそのキャラたらしめる 特徴や要素の集合体です。
まやちゃんの場合で言えば……
ええと、その……体型――じゃなくて!
髪色・髪型・瞳の色といった要素ですね。

キャラクターを「唯一無二」にしたいなら
(胸のサイズだけで差別化するのはさておき……ええ、さておきです)、
この視覚的アイデンティティが十分に定義されている必要があります。
少なすぎれば、モデル側に上書きされてしまう。
多すぎれば、今度はモデルそのものを圧迫してしまう。
既存キャラの場合は、
多くの二次創作によって「多少崩れても成立する幅」が自然と生まれています。
しかし、オリジナルキャラにはそれがありません。
では――
オリジナルキャラクターのLoRAは、どうやって作ればいいのでしょうか?
冒険のはじまり:元になるイラストたち #

最初からうまくいくとは思わないでください。
これは試行錯誤と根気が必要な作業です。
まず必要になるのは、言うまでもなく 元となるイラスト(学習用データ) です。
今回はオリジナルキャラクターが前提なので、当然ながら既存の資料は存在しません。
つまり――自分で用意する必要があります。
そして、ここが重要なポイントですが、
この「最初のイラスト群」こそが、LoRAの出来を左右する最大の要因であり、
同時にキャラクターの視覚的アイデンティティそのものになります。
数ももちろん大事ですが、
それ以上に 質(クオリティ) が重要です。
このあたりは、すぐ後で詳しく説明します。
では、最初のデータがうまくいかなかった場合、どうなるのでしょうか?
その代表的なパターンを、ゆかちゃんで見てみましょう。

- データが少なすぎる、または特徴が弱い場合
→ LoRAはベースモデルに飲み込まれてしまう - 品質・量・バランスが適切な場合
→ LoRAは意図どおりに機能する - 品質は高いが偏りが強い場合
→ キャラが「硬く」なりすぎる
(例:ゆかちゃんの場合、何を生成してもピンクだらけになる)
では、「良いデータセット」とは何でしょうか?
ここで重要になるのが、次の3つの要素です。

- 品質
イラストは十分に鮮明で、破綻がないこと (手の崩れ、指の本数ミスなども含めて)
また、キャラの特徴がはっきり見えること - 数量
モデルが「このキャラはこういう存在だ」と理解できるだけの枚数があること - 多様性
ポーズや角度(極端すぎない範囲で)、服装の違い
バストアップと全身カットの両方を含めること
特に 多様性 は、
オリジナルキャラクターのLoRAでは軽視されがちですが、非常に重要です。
目標は、
「見た目が一貫している」だけでなく、
さまざまなシチュエーションに対応できる柔軟さを持たせること。
例えば、まやちゃんの学習データがすべて制服姿だったとしましょう。
その場合、モデルは「まやちゃん=制服」と強く結びつけてしまい、
水着を指定しても制服が出てくる……なんてことが起きます。

多くの既存ガイドは、
二次創作キャラを前提にしているため、
この「多様性」の問題をあまり扱っていません。
もし、設定上どうしてもバリエーションを増やしにくいキャラ (例えばジェイリンさんや、フォン・ヘルダーンさんのようなケース)であっても、 対処法はちゃんとあります。
それについても、この先で触れていきます。
さて――
「どんなイラストが必要か」が見えてきたところで、 次はそれをどう作っていくかを考えてみましょう。
技術的な話は、必要最低限にとどめます。 というのも、本当に立ちはだかる壁は技術よりも、考え方のほうだからです。
……ええ、身をもって体験しました。
どんなイラストを、何枚作ればいい? #

いい質問ですね、アニャさん。
結局のところ、これは数字の話になります。
オリジナルキャラクターのLoRAを作る場合、 「一体、何枚のイラストが必要なのか?」という疑問に必ずぶつかります。
調べてみると、 「20枚で十分」という意見もあれば、 「数百枚は必要」という話も出てきて、正直混乱しますよね。
先に結論を言ってしまうと――
決まった正解の枚数は存在しません。
必要な枚数は、そのキャラクターが どれだけ“見た目として強いか” に大きく左右されます。
もしキャラクターに
髪型・髪色・目の色・アクセサリーなど、
はっきりした特徴が多い場合は、少ない枚数でも学習しやすいです。
逆に、特徴が控えめなキャラほど、多くのイラストが必要になります。

とはいえ、目安として言うなら――
40枚未満にはしないほうが無難です。
ここまで紹介してきたポイントをきちんと押さえれば、
1つの衣装に限定したキャラクターであれば、
40枚前後でも十分に機能するLoRAを作れる可能性があります。
……そう、ここで重要になってくるのが「どんな種類のイラストを使うか」です。
まず覚えておいてほしいのは、 一貫性は、何よりも強い武器になるということ。
同じ枚数なら、
複数の衣装をバラバラに混ぜるよりも、 1つの衣装で揃えたほうが効果的な場合が多いです。
(これも視覚的アイデンティティの話ですね)
そして、服装についても
「キャラらしさ」が出るポイントを意識してください。
LoRAがうまく学習できていれば、 プロンプト側で指定した一般的な服装については、 モデルがうまく補ってくれるようになります。
とはいえ、実用性を考えると
最低でも2種類以上の衣装は入れておくのがおすすめです。
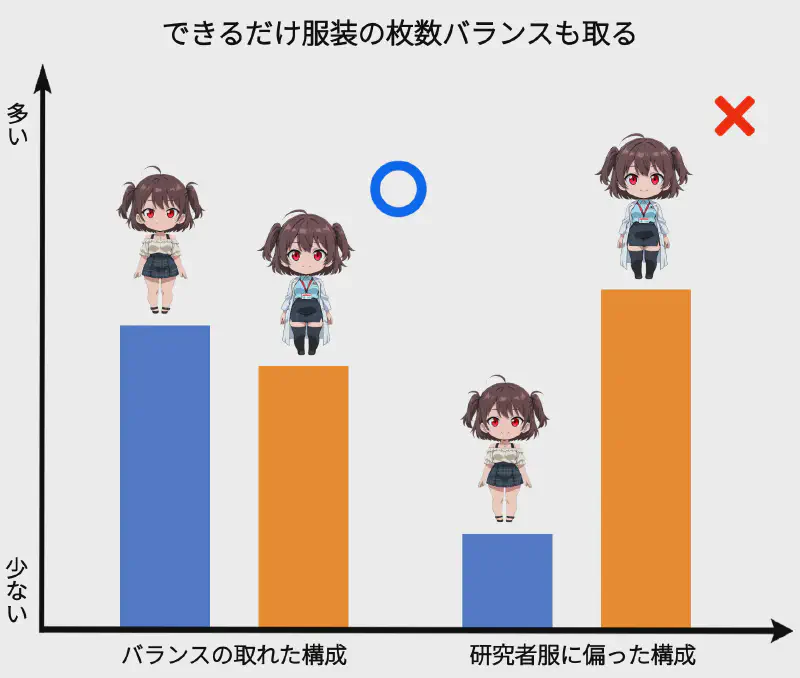
ここで重要なのは「バランス」です。
必ず同じ枚数である必要はありませんが、 極端な偏りは避けましょう。
たとえば――
制服20枚+私服25枚 → OK
制服5枚+私服40枚 → あまり良くない
体型という名の地雷原(?) #
女性キャラクターの場合、もうひとつ厄介なポイントがあります。
それが 体型バランス です。
胸・腰・ヒップといったDanbooru系のタグは確かに存在しますが、
正直なところ――それだけでは安定しません。
では、どうすればいいのか?
彼女たちを裸にしてください!
……ちょっと待ってください。
今、想像した“それ”とは違いますからね?(本当です)
これはれっきとした実用上の理由です。ええ、本当に。
キャラクターの体格そのものに
特別な特徴がない場合(ある意味、顔や髪型と同じです)、 衣服によるノイズを取り除いた状態で体型を確認しておくのは、
LoRA作成において意外と効果があります。
特に問題になりやすいのが胸のサイズです。
どれだけ正確にプロンプトを書いても、 生成結果が大きくブレることがあります
(詠子さんやまやちゃんも、まさにこのケースでした)。
そのため、
・正面
・背面
といった複数角度のイラストを用意し、
「これだ」と思える体型だけをデータとして残す、 というやり方が有効です。
もちろん、
「そこまではちょっと抵抗があるな……」
という方もいるでしょう。
その場合は、露出の少ない水着や
体のラインが分かりやすい衣装でも十分代用できます。
要は、体格がはっきり確認できることが大切なのです。
……とはいえ。
やりすぎは厳禁です。
この手のイラストを入れすぎると、 モデルが 「このキャラのデフォルト状態=服を着ていない」 と誤解してしまう可能性があります。
あくまで“補助的な素材”として、 慎重に、控えめに使いましょう。
厳しくいく?それとも甘くいく? #
もうひとつ、とても大事なルールがあります。
それは――採用するイラストと捨てるイラストを、かなり厳密に選ぶことです。

どれだけ高品質な画像が揃っていても、 数枚の出来の悪いイラストがLoRA全体に与える影響は想像以上に大きいです。
だからこそ、「もったいないな」と思っても、キャラや衣装がズレているものは容赦なく除外しましょう。
もちろん、
・再現が難しい特徴がある
・どうしても妥協が必要な要素がある
――そんなケースもあります。
実際、まやちゃんの強化スーツ系LoRAは、そうした妥協の上で作られています。
ただし原則としては、 キャラクター像や衣装と一致しないイラストは使わない これを基本ルールにしてください。
背景はどうするべき? #
理想的なのは、 学習の主役が「キャラクター」になることです。
LoRAに覚えさせたいのは、 「このキャラがどう座るか」であって、 「椅子なのかソファなのか」ではありません。
背景が情報過多だと、 モデルは本当に重要な要素から注意を逸らされてしまいます。
そこでありがちな解決策が、 「全部、白背景か黒背景にしてしまう」という方法です。
これは確かに機能します――が、副作用もあります。
- 白背景が多すぎる
→ 暗くしたいシーンでも全体が明るくなりがち - 黒背景が多すぎる
→ 通常シーンでも暗く沈みやすくなる
実例として、アニャさんを見てみましょう。
初期データセットでは白背景が多く、 さらに銀髪という要素も重なって、 全体が明るく寄りやすいLoRAになっていました (同一プロンプト・同一シード・同一ベースモデル)。


見ての通り、条件が同じでも 初期版のほうが明るく出ています。
では、どうするか?
おすすめなのは、
- 白背景
- 黒背景
- 室内(寝室・リビングなどのシンプルな背景)
をバランスよく混ぜることです。
「でも背景があると、学習の邪魔になるんじゃ?」
――その通りです。なので、ひと工夫。
depth of field, blurry background
こうしたタグで背景を軽くぼかすことで、 フォーカスはキャラクターに残したまま、 ライティングや色味の多様性だけを取り込めます。
……ややこしそうに聞こえますか? 少しだけ、です。
でも、このポイントを押さえておけば、 知らずに遠回りすることは確実に減ります。
少なくとも、 かつての私が通った試行錯誤ルートは回避できるはずです。
結局、何枚くらい必要なの? #
冒頭の問いに戻りましょう。 「結局、何枚用意すればいいの?」という話です。
私自身の経験から言うと、目安はこんな感じです。
- 単一衣装のキャラクター:40〜60枚
- 複数衣装のキャラクター:1衣装あたり20〜25枚以上
(必要に応じて、前述した体格確認用の画像を追加)
ただし、ここでひとつ注意点があります。 実用上の上限も存在します。
現実的には、250枚を超えないほうが無難です。 なぜなら、枚数を増やしすぎると、LoRAが“硬く”なってしまうからです。
実際、初期のまやちゃん・ゆかちゃんのLoRAはこの問題を抱えていました。
ベースモデルのスタイルを完全に上書きしてしまい、 ライティングや雰囲気の柔軟性が大きく損なわれていたのです。
ここで、実例を見てみましょう
(同一プロンプト・同一シード・同一ベースモデル)。


よく見ると、初期LoRAでは ゆかちゃんの髪のピンクが顔にまで回り込み、 どんなモデル・どんなスタイルでも強いチークとして残っています。
これは、
- 画像数が多すぎたこと
- さらに別の要因(後ほど触れます)
が重なり、LoRAが特定の見た目にロックしてしまったためです。
結果として、ベースモデル側で調整する余地がほぼなくなっていました。
ポーズとアングルの話 #

完璧だよ、湖乃美さん。
……そして、この「ポーズ」と「アングル」も、 LoRAの質を左右するのに意外と見落とされがちなポイントです。
データセットを作るとき、 「どんな角度・構図を使うべきか?」という疑問が必ず出てきます。
記事の最後に、私が普段使っているワイルドカードを載せますが、 ここでは基本的な考え方だけまとめておきます。
- 構図は必ず変化をつけること
正面アップばかり、は避ける - バストアップ・上半身・全身を混ぜること
ただし、やや全身寄りが理想
→ 学習後、全身生成が安定します - アングルは変えてOK、でも極端はNG
魚眼・超ローアングル・超ハイアングルなどは避ける
例として、まやちゃんで 「問題なし」「少し複雑(許容)」「やりすぎ(避ける)」 を並べてみましょう。

どうでしょう?
そこまで難しい話ではありませんよね。
また、衣装によっては(あるいは……衣装がない場合でも、ゴホン) 背面カットを数枚入れておくと有効です。
特に、
- 背中に装飾がある服
- メカスーツやアーマー
など、ベースモデル側の知識が薄い場合には効果的です。
ポーズと表情のバランス #
構図が決まったら、次はポーズと表情です。
ここも「多ければいい」わけではありません。
おすすめは以下の目安です。
- ポーズ:7〜8種類
- 表情:4〜5種類(それ以上は不要)
この組み合わせを使ってデータセットを構成します。
ワイルドカードが非常に役立つ理由が、ここにあります。
同じポーズを複数回使っても構いません。
- 表情が違う
- 解像度が違う
こうした差があれば、十分意味があります。
さて、これで 「何を」「どういう構図で」「どのくらい」用意すべきか が見えてきました。
次は、 解像度についてです。
解像度はどうする? #

モデルが複数の解像度で画像を出力できるように、 学習用のイラストも、解像度やアスペクト比を少しずつ変えるのがおすすめです。
基本的な考え方としては、 複数の解像度に均等に割り振る、これだけでOKです。
サイズが多少大きくても心配はいりません。
ほとんどの学習ツールは、トレーニング時に自動でリサイズしてくれます。
目安としては、1解像度あたり4〜5枚あれば十分です。
参考までに、私がよく使っている解像度はこちらです。
- 正方形:1024×1024
- 横長:1216×832 / 1344×768 / 1536×1024
- 縦長:832×1216 / 768×1344 / 1024×1536
もちろん、これに限る必要はありません。
正方形・横長・縦長の3タイプが揃っていれば問題なしです。
こうしておくことで、
LoRA完成後にさまざまな解像度で安定してキャラを生成できるようになります。
さて、データセット準備もいよいよ大詰めです。
残る重要ポイントはあと2つ。
どのモデルを使うべき? #

わかるよ、ゆかちゃん。
モデル、多すぎますよね……。
性能も得意分野もバラバラで、 データセット用にどれを使うべきか迷うのは当然です。
結論から言うと、自分が好きなモデルでOKです。
ただし、ひとつだけおすすめがあるとすれば――
スタイルがはっきりしているモデルを選ぶ、という点です。
特定の作家風スタイルを使う、あるいは複数の作家スタイルを混ぜたい場合を除けば、 「このモデルっぽい絵だな」と一目でわかるものが向いています。
個人的には、次の2つをよくおすすめしています。
- WAI-Illustrious-XL
(私自身のLoRA作成でも使用。個性が強く、なおかつ応用力も高い) - Ikastrious


大事なのは、
「自分が思い描くキャラクター像が、素直に出てくるかどうか」 です。
あとはもう、完全に好みの問題ですね。
さて、データセット準備の最後の話題に入りましょう。
プロンプトの組み方です。
学習用イラストのプロンプトのコツ #
プロンプトは自由に書いて構いませんが、 作業を楽にするためのコツをいくつか挙げておきます。
- 屋外シーンは避ける(光が複雑になりがち)
- 部屋はシンプルに
例:indoors, bedroom, blurry background, depth of field - グラデーション背景なら
gradient background, grey background - ポジティブ/ネガティブは必要最小限に
- Illustrious / NoobAI-XL系では自然文よりDanbooruタグ優先
(例:a girl standing in a field→1girl, solo, standing, field)
これで、学習用データの準備は完了です。
少し多めに作っておくのもポイントです。
あとから「これは微妙だな」と思った画像を削除できる余裕ができます。
では――
次のステップへ進みましょう!
キャプション(タグ付け) #
キャプションって何? #

簡単ですよ、まやちゃん。
それがキャプション(いわゆるタグ付け)の結果です。
……キャプション?
そうですね。なんだか宇宙人の暗号みたいな名前ですが(笑)、実際はLoRAを学習させるときに「何が重要か」をモデルに教える方法なんです。
もう少し噛み砕いて言うと、 キャプションは「この画像に含まれる要素のうち、本質的なものと状況的なものを区別する」ための仕組みです。
……余計わからなくなりました?
大丈夫です。ここから順に説明していきます。
モデルが画像を理解するための情報源は、大きく分けて2つあります。
flowchart LR
A["画像
(視覚情報)
見た目・形・色・構図"] -->|視覚情報を提供| C(["LoRAの学習
両方の情報をもとに学習する"])
B["キャプション
(言語情報)
重要な要素を言葉で指定"] -->|言語による指定| C
style A fill:#d5e4f5,stroke:#333,color:black,font-weight: bold;
style B fill:#fdd9bf,stroke:#333,color:black,font-weight: bold;
style C font-weight:bold,fill:#e2dcc8,stroke:#333,color:black;
linkStyle 0 stroke:#111,stroke-width:2px;
linkStyle 1 stroke:#111,stroke-width:2px;
ひとつは画像そのものです。
見た目、色、形、構図……いわゆる視覚情報ですね。
もうひとつがキャプションです。
これは画像に対応する短いテキストで、「この画像で重要な要素」を言葉で指定するものです。
LoRAは、この視覚情報+言語情報の両方を使って学習します。
そのため、キャプションはLoRA学習において必須になります。
キャプションって実際には何? #
実際のキャプションは、画像と同じ名前を持つ小さなテキストファイルです。
中身は、その画像を表すタグの羅列になります。
Illustrious や NoobAI-XL 系のLoRA学習では、 Danbooruタグのみを使うのが基本です (他のモデルでは自然文が使える場合もあります)。
例えば、これは私が実際に使っているキャプションの一例です。
mayaalt, 1girl, very long hair, blue eyes, white background, light blue hair, blunt bangs, covered navel, dutch angle, helmet, shaded face, power armor, hair twirling, psuitbgata, red armor
キャプションは学習工程の一部ですが、 実はここで失敗する人がとても多いポイントでもあります。
このガイドでは、 「どうすれば効果的にキャプションを書けるか」を順を追って説明していきます。
その前に、ぜひ押さえておきたい重要なポイントがいくつかあります。

トリガーワードは必須 #
まず、オリジナルキャラには必ずトリガーワードを用意してください。
これはモデルがすでに知っている単語と被らない、 完全に固有の名前である必要があります。 (英数字でも問題ありません)
このトリガーワードが、 キャプションに書かれていない特徴すべてを「ひとまとめ」にしてくれます。
例えば、私の場合は以下のようにしています。
- 通常のまやちゃん →
hirukawamaya - 変身後のまやちゃん →
mayaalt
この単語を見た瞬間、 モデルは「このキャラを出せばいいんだな」と理解します。
キャプションは“柔軟性”を決める #
次に重要なのが、 キャプションに何を書くかで、LoRAの柔軟性が決まるという点です。
たとえば、詠子さんの特徴的な髪型「ツーサイドアップ」。
もし学習用キャプションに two side up を入れておくと、 その髪型はタグを指定したときだけ出るようになります。


逆に、two side up をキャプションから外してしまうと、 トリガーワード(この場合 aramakieiko)を使った時点で 常にその髪型が固定されて出てしまいます。
もうひとつ例を挙げると、 初期のゆかちゃんLoRAで blush をキャプションに残しておけば、 顔全体がピンクに寄りすぎる問題は、かなり抑えられたはずです。
まとめると #
- 必ず固有のトリガーワードを使う
- トリガーワードは、キャプションに書かれていない特徴をまとめて吸収する
- キャプションに残したタグは、使ったときだけ効果が出る → 柔軟性が高くなる
理論はこれくらいで十分でしょう。
次は実践編です。
実際にどうやってキャプションを書くのかを見ていきましょう!
では、実際にどうやってキャプションを付けるのか? #

まず最初に言っておきますが、 生成時に使ったプロンプトをそのままキャプションに流用する──これは正解ではありません。
キャプションに必要なのは、 「そのイラストを正しく把握するために最低限必要な情報」だけです。
実際のイラストには、 プロンプトでは意図していなかった要素や、偶然生成された特徴が含まれていることも多いです。
それらも含めて把握しておかないと、LoRAは正しく学習できません。
では、どうするのか?
答えはひとつです。
手作業ではやりません。
自動キャプションという強い味方 #
ありがたいことに世の中には、 画像を入力すると自動でDanbooruタグを付けてくれるモデルがいくつも存在します。
これらは「そのまま使える完璧なキャプション」を出してくれるわけではありません (あとで修正は必要です)が、ゼロから全部書くより圧倒的に速いです。
しかも、
- 高性能なグラボがなくても動く
- 生成は別PCやクラウドでやって、キャプションだけローカルで付ける
──といった運用も可能です(速度は落ちますが)。
キャプション用のソフトは色々ありますが、 今回は私が実際に使っていて、なおかつ今も比較的メンテナンスされているものを紹介します。
それが taggui です。
taggui は、
データセットとキャプションをGUIで管理・編集できるツールです。
正直、機能はかなり多いです。
でも今回の用途に必要な部分だけ使えば十分ですし、 操作も比較的直感的で、初心者にも優しい部類だと思います。
すでにタグ付けに慣れている方は、 このセクションは読み飛ばしてもOKです。
taggui は Windows / Linux対応です。
残念ながら、macOS向けで同等のキャプションツールは見つけられませんでした
(そもそもMacを持っていない、というのもあります)。
taggui の導入と起動 #
taggui は以下からダウンロードできます。
👉 https://github.com/jhc13/taggui/releases/tag/v1.34.0
- Windows:対応する
.7zをダウンロードして展開するだけです(インストール不要) - Linux:……まあ、わかりますよね?(笑)
NVIDIA製のグラボがあれば、 それを使ってキャプション生成を高速化できます。
画像を読み込む #
まずは、 キャプションを付けたい画像群(=データセット)を任意のフォルダにまとめておきます。
その後、taggui を起動してください。
起動すると、こんな画面が表示されるはずです
(ここでは私の実データセットを例にしています)。
……英語ですね。 残念ながら、日本語でまともに動くツールは見当たりませんでした(少なくとも、私の知る限りでは)。
なのでこのガイドでは、
できるだけ画像ベースで手順を説明します。
それでも迷ったら、GPTくんに聞きましょう(笑)
まずはメニューから
File → Load Directory を選び、 画像が入っているフォルダを指定します。
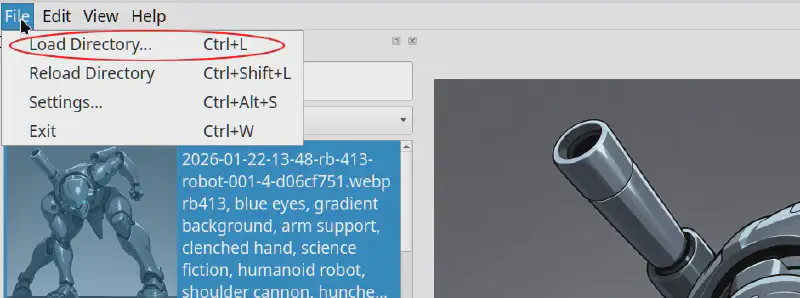
左側のパネルに画像名が一覧表示されます。
この時点では「名前だけ」なのが正しい状態です。
まだキャプションを付けていないからです。
自動キャプションを実行する #
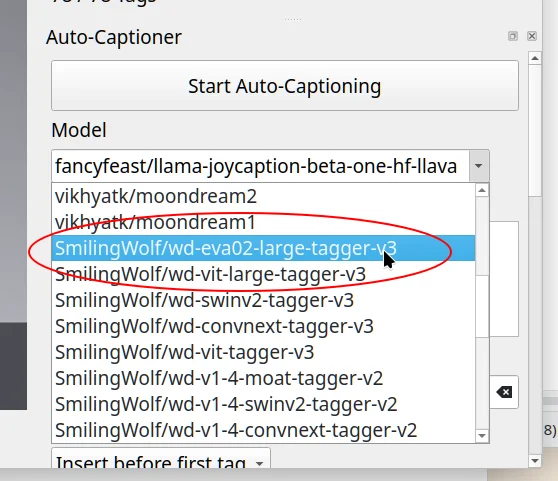
次に、画面右側の Auto Captioner パネルを探します。
モデルは
SmilingWolf/wd-eva-02-large-tagger
を選択してください。
他にもモデルはありますが、
Danbooruタグ用途ではこれがかなり優秀です。
選択したら、
Start Auto-Captioning をクリックします。
処理時間は、
- グラボあり → 数十秒〜1分程度
- グラボなし → 数分(3〜4分くらい)
という感じです。
モデル自体のダウンロードが少し重いので、 ネット回線はそれなりに速い方が快適です。
キャプション生成完了 #
処理が終わると、
各画像の横にテキストが表示されます。
これが自動生成されたキャプションです。
フォルダを直接見ると、 画像ファイルの横に .txt ファイルが大量にできているはずです。
これが学習時に使われるので、消さずにそのまま置いておいてください。
ただし──
このままではまだ使えません。
トリガーワードを追加する #
次にやるべきことは、 トリガーワードの追加です。
そして重要なのは、すべてのキャプションで「先頭」に来るようにすることです。
(タグは前にあるほど重みが強いです)
まず、画像をすべて選択します。
- 任意の画像を右クリック →「Select All Images」
- もしくは 1枚選んで
Ctrl + A
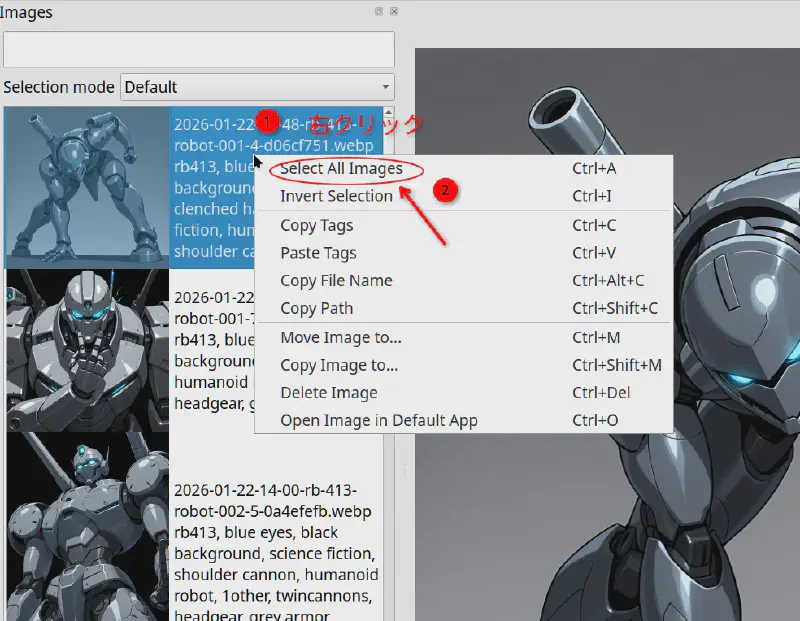
次に、右側の Image tags パネルに 自分のトリガーワードを入力して Enter。
「すべての画像に適用するか?」と聞かれるので Yes を選びます。

トリガーワードを先頭へ移動 #
追加しただけだと、 トリガーワードが文中のどこかに混ざっている状態になります。
これを先頭に移動します。
Edit → Batch Reorder Tags を選択してください。
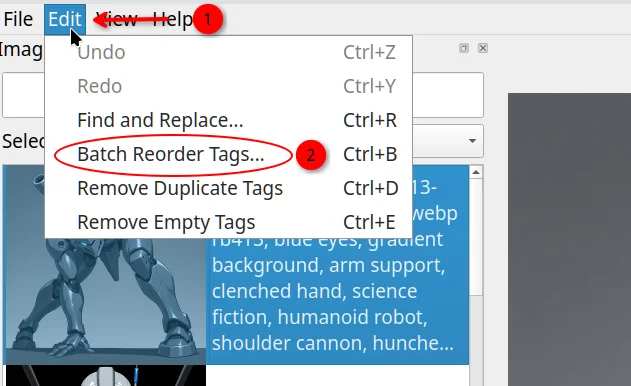
表示されたウィンドウで、
- 「Tags to move to front」にトリガーワードを入力
- Move Tags to Front をクリック
これでOKです。
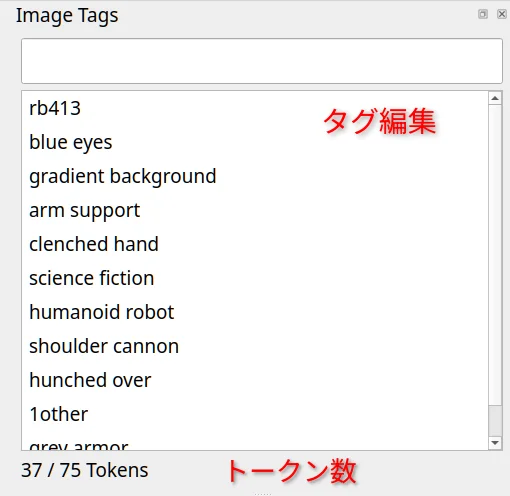
タグの編集方法 #
ここからが本番です。
- Image tags パネル
- 追加:入力して Enter
- 削除:選択して
Del - 名前変更:ダブルクリック
- 複数画像に対して操作すると確認ダイアログが出ます
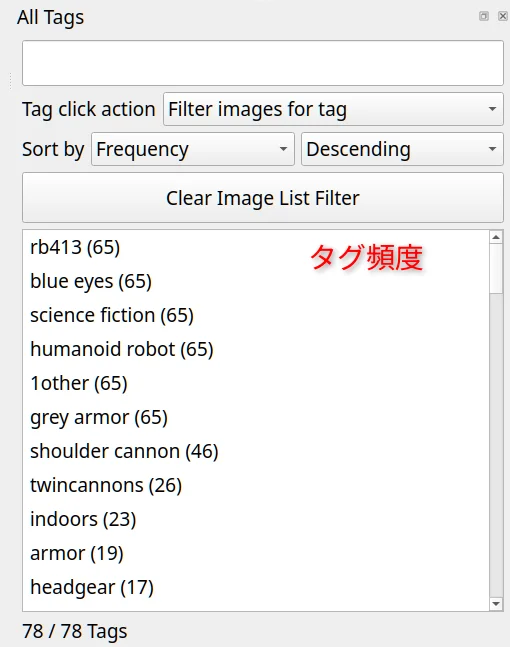
- All tags パネル
- 各タグが何枚の画像に付いているか確認できます
- タグをクリックすると、そのタグを含む画像だけを表示します
- 選択して
Delで一括削除も可能です
変更は即時反映されますが、
Edit メニューから Undo / Redo も可能なので安心してください。
ここまでで、
- 自動キャプション生成
- トリガーワードの追加
- タグ編集の準備
が整いました。
次はいよいよ、
どのタグを残し、どのタグを消すのか──
つまり「キャプションの中身そのもの」を詰めていく工程です。
これはツール依存ではない話なので、 次のセクションでじっくり解説します。
キャプション整理の極意──本当に残すべき「核心」 #

自動キャプションを実行すると、 ほとんどの場合、画像には非常に多くのタグが付与されます。
しかし、そのすべてが LoRA学習に有用というわけではありません。
むしろ、多くのタグは不要、あるいは学習の邪魔になることさえあります。
目指すべきなのは、 「その画像を正しく説明するために最低限必要なタグだけ」を残すことです。
加えて、学習ソフトによっては キャプションのトークン数に上限がある点にも注意が必要です。
- 最大 75トークン までしか使われないもの
- 150トークン まで対応しているもの
後者であっても、 不要なタグで枠を埋めてしまう意味はありません。
では、 どのタグを削除し、どれを残すべきなのでしょうか。
安心して削除できるタグ #
- 明らかに誤っているタグ
(例:virtual youtuber、誤った髪色など) - 背景に関する詳細タグ
(indoors以外は基本的に不要。
blurry backgroundやdepth of fieldは残して問題ありません) - 細かすぎる解剖学タグ
(collarbone、biceps、feet、thighsなど)
→ 人体構造はモデルが十分に理解しています - 意味が重複しているタグ
(例:v over eyeがあればvは不要) - 情報量の少ない服装タグ
(jacketよりbrown jacketを残す、など) - トリガーワードに吸収させたい特徴
逆に、残すべきタグ #
- 自分で制御したい要素
(髪色、髪型、目の色など) - ネガティブに使いたいタグ
(常に出てしまう要素。例:blush) - ポーズに関するタグ
- 具体的な服装タグ
体型に関する特徴(胸サイズなど)を指定したい場合は、 すべての画像で一貫して同じタグが付いているかを必ず確認してください。 (同一キャプション内でサイズが食い違っていることもあります)
整理後キャプションの例 #
以下は、アニャさんのデータセットから 不要なタグを整理した後のキャプション例です。
nazonoanya, 1girl, very long hair, smile, white background, green eyes, blue hair, jacket, grey hair, ponytail, black thighhighs, blue necktie, office lady, medium breasts, skirt suit, pencil skirt
この例では、 OL衣装を表すタグを必要最小限まで整理しています。
たとえば skirt suit のみを残し、 細かいディテールを省略することも可能です。
その分、 後から衣装の細部を変えたい場合の柔軟性は下がりますが、 「絶対に変えない前提」であれば問題ありません。
記事の最後には、 整理済みキャプション付きの簡易データセット例も掲載しています。
ぜひ参考にしてください。
ここまでで、 キャプションの準備はすべて整いました。
次はいよいよ──
LoRAの学習そのものに進みます。
LoRAはどうやって学習させればいい? #

このセクションで紹介する設定を使う場合、最低でもVRAM 16GBが必要です。
環境は人それぞれ異なり、 LoRA学習用のツールも複数存在します。
そのため、ここでは 特定ツールの完全な操作手順は扱いません。
個人的には、 この系統のモデルで最も広く使われている kohya_ss をおすすめします。
すでに分かりやすい解説記事も公開されています。


これらを参考にすれば、 学習自体は問題なく始められるはずです。
その前に、どうしても伝えたいこと #
ここからが本題です。
私が本当に伝えたいのは、学習パラメータの考え方です。
正直に言うと、 私はここで約2か月、遠回りをしました。
思うような結果が出ず、 半ば試行錯誤の末に出会ったのが、 以下のCivitaiにあるプリセットです。
👉 https://civitai.com/models/850658/illustrious-lora-training-guide

これをベースに ごくわずかな調整を加えたことで、 ようやく「狙い通りのLoRA」を作れるようになりました。
重要ポイント①:ベースモデル #
まず一つ目は、 どのベースモデルを使うかです。
これは、 作成したLoRAが他のモデルでも使えるかどうかに直結します。
個人的に今でもおすすめしているのは、 Illustrious 0.1(初期リリース版) です。
👉 https://huggingface.co/OnomaAIResearch/Illustrious-xl-early-release-v0
このモデルは、
- 他モデルとの互換性が高い
- スタイルの癖が比較的素直
という理由から、 汎用性の高いLoRAを作りやすいと感じています。
実際、私のLoRAはすべてこれをベースにしています。
もちろん、 互換性をそれほど重視しない場合は、 好みのモデルを使っても問題ありません。
重要ポイント②:学習パラメータ #
もう一つの重要点が、 学習パラメータの設定です。
少しだけ数式的な話が出てきますが、 ここでは必要最低限に留めます。
考えるべきポイントは大きく2つだけです。
- どれくらい強く画像を見せるか
- どれくらいの速さで学習させるか
まずは、後者から見ていきましょう。
速すぎる?遅すぎる? #

LoRAの学習は、 選んだベースモデルに対して 同じ画像群を何周も見せることで進んでいきます。
この「1周分」のことを epoch(エポック) と呼びます。
ここで重要なのは、 一気に覚えさせすぎないことです。
- 学習が速すぎると → モデルが硬直し、融通が利かなくなります
- 学習が遅すぎると → いつまで経っても特徴を覚えません
この「学習の速さ」を制御するのが、 いわゆる learning rate(学習率) です。
さらにもうひとつ、 各エポックのたびに モデルが「少しだけ過去を忘れる」仕組みがあります。
これが learning loss です。
この2つを適切に調整することで、 「覚えすぎず、忘れすぎない」 ちょうどよいバランスを作ることができます。
難しい?なら自動化しましょう #
多くのガイドでは、 これらのパラメータに具体的な数値が書かれていますが、 正直なところ、調整はかなり面倒です。
幸いなことに、 これらを自動で最適化してくれる手法が存在します。
先ほど紹介したプリセットでは、 Prodigy という方式が使われており、
- 学習率
- ロスの挙動
を自動的に調整してくれます。
しかも、 オリジナルキャラクターの特徴を しっかり捉えるため、 やや攻めた設定になっています。
このプリセットを使う場合、 細かい数値で悩む必要はほとんどありません。
より技術的な仕組みに興味がある場合は、 先ほど紹介した学習ガイドを参照してください。
次は、 学習回数・エポック数・出力の見極め方について説明していきます。
学習回数の考え方:数字とどう向き合うか #

もうひとつ、必ず考えておく必要があるのが、 「どれくらいの長さで学習させるか」 という点です。
ガイドによっては「エポック数」が強調されがちですが、 私の経験では、より重要なのは ステップ数になります。
ここでいう 1ステップ とは、 データセット内の画像1枚に対して行われる、1回分の学習処理を指します。
前のセクションで触れた通り、 モデルは同じ画像を何度か繰り返し見ることで、 はじめてキャラクターの特徴を安定して学習できます。
つまり、
ステップ数はそのまま 学習にかける時間の長さと考えて問題ありません。
- ステップ数が少なすぎる → 特徴を十分に覚えない
- ステップ数が多すぎる → LoRAが硬直し、融通が利かなくなる
ここでも、いつものバランスの話になります。
さらにややこしくなる要素:リピートとバッチサイズ #
ここで、少し話を複雑にする要素が2つ登場します。
まず リピート(repeat)。
これは「1エポックの中で、同じ画像を何回使うか」という設定です。
十分な枚数(目安として60枚以上)がある場合、 リピート2回で基本的には問題ありません。
次に バッチサイズ(batch size)。 これは「同時に何枚の画像を学習させるか」を表します。
実用的な観点では、 最低でもバッチサイズ2は確保したいところです。
(これ以下だと、学習効率がかなり落ちてしまいます)
では、結局どれくらいが目安か #
ここまでの話を踏まえたうえで、 私自身の経験則をまとめると、目安は次の通りです。
- 単一衣装キャラ(60枚前後)
→ 1500〜1900ステップ - 複数衣装キャラ(100枚以上)
→ 2500〜3500ステップ
この「目標ステップ数」をもとに、 必要なエポック数を逆算していく形になります。
エポックとステップの関係 #
覚えているでしょうか。 データセットを1周学習すること=1エポックでした。
ステップ数は、次の式で求められます。
$$ステップ = (\frac{イラスト数 \times リピート}{バッチサイズ}) \times エポック$$

大丈夫です、ゆかちゃん。
実際に計算してみると、そこまで難しくありません。
具体例で確認してみましょう #
例1:詠子さんの場合
- 画像数:226枚
- リピート:2
- バッチサイズ:2
この条件では、 1エポックあたりのステップ数は 226 になります。
これを 16エポック 回すと、
- 226 × 16 = 3616ステップ
例2:まやちゃんの場合
- 画像数:190枚
- リピート:2
- バッチサイズ:2
1エポックあたり 190ステップ。
16エポックで、
- 190 × 16 = 3040ステップ
シンプルな覚え方 #
もし、
- バッチサイズ = 2
- リピート = 2
で固定する場合は、
「画像枚数 × エポック数 ≒ ステップ数」
と考えてしまって構いません。
目標としているステップ数に近づくように、 エポック数を調整すればOKです。
この数値は、あとで学習設定に使う重要な値なので、メモしておくことをおすすめします。
学習プリセットの使い方 #
このプリセットはそのまま実行するものではありません。
必ずご自身の環境に合わせた調整が必要です。
まず、「使用リソース」セクションから 学習プリセットをダウンロードし、kohya_ss に読み込みます。
その後、最低限変更する必要があるのは次の2点です。
- 出力ファイル名(任意の名前に変更)
- エポック数(上で計算した値に合わせる)
プリセットの読み込み方法や 各項目の編集手順については、 前のセクションで紹介したガイドを参照してください。
ここまで来れば、 学習設定の土台はほぼ完成です。
最後の仕上げ:学習とチェック #

すべての準備が整ったら、 いよいよ学習を開始します。
学習時間は環境によって差がありますが、 私のグラボでは 数時間程度 かかりました。
完了するまで待ちましょう。
学習が終わったら、 次に行うべきことはひとつ。
完成したLoRAが、想定通りに動いているかの確認です。
では、何を見ればいいのでしょうか?
ここで、詠子さんに簡単に整理してもらいましょう。

チェックすべきポイント #
-
視覚的アイデンティティ
データセットに含まれる衣装のひとつを使い、 普段使っているモデルで生成してみてください。
キャラクターとしての「らしさ」が保たれていますか?
ベースモデルの画風に引っ張られすぎていなければ、良い兆候です。 -
視覚的な破綻
色のにじみや破綻が出ていないか確認します。
(……覚えていますか?ゆかちゃんの顔の事故) -
柔軟性
学習に使ったポーズ・衣装を試したあと、 あえて使っていないものも指定してみましょう。
照明や構図を変えても、破綻せずに対応できていれば理想的です。 -
LoRA強度
強度 1.0 から 0.5 まで段階的に試します。
低い値でしか正しく出ない場合は、 学習しすぎ(オーバートレーニング)の可能性があります。
すべて問題なければ……
胸を張っていい出来と言っていいでしょう。お疲れさまでした。
うまくいかなかった場合は? #
もし結果に違和感がある場合は、 まずデータセットを見直してみてください。
私自身、 カイレスさんのLoRAを作ったとき、
- 笑顔や笑いの表情を 1枚もデータセットに入れていなかった
という単純なミスをしていました。
その結果、 笑わせようとすると顔が物理的に崩壊するという なかなかホラーな挙動に……。
最初に書いた通り、 一発で成功することの方が稀です。
でも、 一度コツを掴んでしまえば、 次からは驚くほどスムーズに作れるようになります。
焦らず、少しずつ経験を積んでいきましょう。
最後に #

正直なところ、 これは私がこれまで書いた中でも 最も長く、最も詰め込んだガイドになりました。
それでも、 オリジナルキャラクターのLoRAを作りたい人にとって、 少しでも近道になれば嬉しく思います。
「ここが分かりにくかった」
「ここは別のやり方がある」など、 気づいた点があれば、ぜひ X で教えてください。
それでは、また次回!
Einarでした。
使用リソース #
サンプルデータセット #
アニャさんのLoRA学習で使用した キャプション整理済みの簡易データセット。
ダウンロードkohya_ss 学習プリセット #
本記事で解説している 学習パラメータ入りのサンプルプリセット。
ダウンロードワイルドカード(データ生成補助) #
データセット用イラストを生成する際に使える ランダム選択用ワイルドカード集。
※ 使用するには、 ワイルドカードをネイティブ対応しているWebUI(SD.Next)または対応アドオン(A1111 / Reforge / ComfyUI)が必要。
ポーズ #
データセット生成向け 各種ポーズ用ワイルドカード。
ダウンロード表情 #
データセット生成向け 各種表情用ワイルドカード。
ダウンロードアングル・構図・背景 #
データセット生成向け カメラアングル/構図/背景用ワイルドカード。
ダウンロード